什么是 LFU 缓存算法?
LFU 是什么?
LFU 是 “Least Frequently Used” 的缩写。
LFU Cache 是一种常见的缓存管理算法,它的设计思想是当缓存满时,淘汰缓存中最不经常使用的数据。通过这个简单的机制来保证缓存中存储的数据尽可能的有用,从而提高缓存的命中率。
LFU 的应用场景
LFU 的经典应用场景是 HTTP 缓存代理(proxy)应用,它位于网络服务和用户之间,如下图所示:
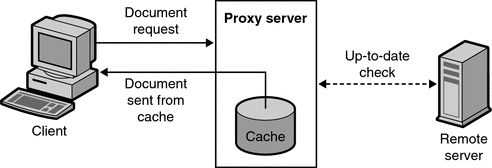
(图片来源 Oracle)
缓存代理的作用是在缓存服务器上的有限的存储空间尽可能的缓存热门的静态文件,从而加快网络服务的响应速度和优化网络的利用率。其实现的代价应尽可能的小,以保证在高负载下代理仍能正常工作。
LRU 也是一个不错的选择,但在某些特定的场景下,比如访问一系列不同的数据,这些数据的访问顺序是轮询的,这会导致缓存不断的被替换,LFU 可能会失效。
接口设计
class LFUCache {
Public:
// 1. Construct a cache with capacity size
LFUCache(int capacity) {}
// 1. retrieve the value by its key
// 2. return -1 if not found
int get(int key) {}
// 1. put the key-value pair into the cache
// 2. delete the least frequently used data if the cache is full
// 3. if multiple data have the same frequency, delete the least recently used one
void put(int key, int val) {}
}
数据结构设计
LFU 缓存的实现依赖于两个哈希表,以实现 get 和 put 操作的时间复杂度为 O(1)。
第一个哈希表用于存储键值对。
第二个哈希表用于存储每个键的访问频率。
每个键的访问频率用于确定最不经常使用的数据的顺序。
最不经常使用的数据是指访问频率最小的数据,如果多个数据的访问频率相同,那么最不经常使用的数据是最近最久未被访问的数据。
C++ 示例代码
#include <list>
#include <random>
#include <iostream>
#include <unordered_map>
using namespace std;
struct Node
{
int key;
int value;
int freqeuncy;
Node(int k, int v, int f) : key(k), value(v), freqeuncy(f) {}
};
class LFUCache
{
private:
int minFreq; // minimum frequency of the cache
int capacity; // maximum capacity of the cache
unordered_map<int, list<Node>::iterator> key_table; // key to iterator mapping table
unordered_map<int, list<Node>> freq_table; // frequency to list mapping table
public:
int HIT = 0;
int MISS = 0;
LFUCache(int capacity){
this->capacity = capacity;
minFreq = 0;
key_table.clear();
freq_table.clear();
}
int get(const int &key)
{
// if the capacity is 0, return -1
if (capacity == 0)
{
return -1;
}
// find the iterator of the node
auto it = key_table.find(key);
// if the node is not found, return -1
if (it == key_table.end())
{
MISS++;
return -1;
}
list<Node>::iterator node = it->second;
int value = node->value;
int freq = node->freqeuncy;
freq_table[freq].erase(node);
// if the list is empty, remove it from the map, and update the minimum frequency
if (freq_table[minFreq].size() == 0)
{
freq_table.erase(freq);
// if the minimum frequency is equal to current frequency, increase the min_freq
if (minFreq == freq)
minFreq++;
}
// insert the node to the freq + 1 position
freq_table[freq + 1].push_front(Node(key, value, freq + 1));
// update the iterator in the map
key_table[key] = freq_table[freq + 1].begin();
HIT++;
return value;
}
void put(int key, int value)
{
// if the capacity is 0, return
if (capacity == 0)
return;
// find the iterator of the node
auto it = key_table.find(key);
if (it == key_table.end())
{
// if the key is not in the cache, will insert it
// check the capacity first
if (key_table.size() == capacity)
{
// if the cache is full, remove the least frequently used node
// get the last node by the minimum frequency
auto minNode = freq_table[minFreq].back();
key_table.erase(minNode.key);
// insert the new node now
freq_table[minFreq].pop_back();
if (freq_table[minFreq].size() == 0)
{
// if the list is empty, remove it from the map
freq_table.erase(minFreq);
}
}
// update the iterator in the map
minFreq = 1;
freq_table[minFreq].push_front(Node(key, value, minFreq));
key_table[key] = freq_table[minFreq].begin();
}
else
{
// if the key is in the cache, update the frequency
list<Node>::iterator node = it->second;
int freq = node->freqeuncy;
freq_table[freq].erase(node);
if (freq_table[freq].size() == 0)
{
// remove old frequency
freq_table.erase(freq);
// if the min_freq = cur_freq, update the min_freq
if (minFreq == freq)
minFreq++;
}
// insert the node to the freq + 1 position
freq_table[freq + 1].push_front(Node(key, value, freq + 1));
// update the iterator in the map
key_table[key] = freq_table[freq + 1].begin();
}
}
void clear()
{
key_table.clear();
freq_table.clear();
minFreq = 0;
HIT = 0;
MISS = 0;
}
};
void testCase(){
// from leetcode example
LFUCache cache(2);
cache.put(1, 1);
cache.put(2, 2);
cout << cache.get(1) << endl; // returns 1
cache.put(3, 3); // evicts key 2
cout << cache.get(2) << endl; // returns -1 (not found)
cout << cache.get(3) << endl; // returns 3.
cache.put(4, 4); // evicts key 1.
cout << cache.get(1) << endl; // returns -1 (not found)
cout << cache.get(3) << endl; // returns 3
cout << cache.get(4) << endl; // returns 4
}
int main()
{
// testCase();
const int CAPACITY = 200;
const int NUM = 1000;
LFUCache cache(CAPACITY);
// sequential access
cout << "Sequential Access" << endl;
cache.clear();
for (int i = 0; i < NUM; ++i)
{
if (cache.get(i) == -1)
{
cache.put(i, i);
}
}
cout << "HIT: " << cache.HIT << "\t\tMISS: " << cache.MISS
<< "\t\tHit Rate: " << (double)cache.HIT / (cache.HIT + cache.MISS) << endl;
// random access with uniform distribution
cout << "Random Access with Uniform Distribution" << endl;
cache.clear();
random_device rd;
mt19937 gen(rd());
uniform_int_distribution<> dis(0, NUM);
for (int i = 0; i < NUM; ++i)
{
int key = dis(gen);
if (cache.get(key) == -1)
{
cache.put(key, key);
}
}
cout << "HIT: " << cache.HIT << "\t\tMISS: " << cache.MISS
<< "\t\tHit Rate: " << (double)cache.HIT / (cache.HIT + cache.MISS) << endl;
// random access with normal distribution
cout << "Random Access with Normal Distribution" << endl;
cache.clear();
int mu = NUM / 2;
int sigma = NUM / 6;
normal_distribution<> ndis(mu, sigma);
for (int i = 0; i < NUM*10; ++i)
{
int key = ndis(gen);
if (cache.get(key) == -1)
{
cache.put(key, key);
}
}
cout << "HIT: " << cache.HIT << "\t\tMISS: " << cache.MISS
<< "\t\tHit Rate: " << (double)cache.HIT / (cache.HIT + cache.MISS) << endl;
return 0;
}
LFU 的潜在问题
热点数据不易被移出缓存:有些数据可能只是在短时间内被高频访问。但是它在这段时间内累积了很高的频率,所以在它的热点期过后也会长时间留在缓存中不易被移出。
新加入的数据更容易被移出缓存:如果只是移出频率最小的数据,那么新加入的数据会更容易被移出。这是因为新加入的数据的频率默认为 1,而老数据累积了很长时间,所以频率比新数据要高多。
空间问题:如果记录了所有数据的访问信息,那么会占用更多的内存空间。
LFU 的一些改进
LFU-Aging
LFU-Aging 是一个混合的淘汰策略,它结合了 LFU 和 LRU 的一些特点。和 LFU 一样,它会记录每个 key 的访问频率,但是它也会考虑 key 的年龄,使用衰减因子来赋予最近访问过的 key 更高优先级。
LFU-Aging 淘汰策略是通过一个计数器来实现的。每次访问一个 key 时,计数器都会增加。随着时间的推移,计数器会使用衰减因子进行衰减。用户可以通过配置来设置衰减因子。当一个 key 被移出缓存时,计数器值最小的 key 会被移出。
通过结合 LFU 和 LRU 的一些特点,LFU-Aging 旨在在两种方法之间取得平衡,考虑到 key 的访问频率和访问的最近性。这可以帮助防止缓存淘汰和填充的问题,可以提高缓存的整体性能。
在 Redis 中,为了解决上面三个问题,LFU-Aging 引入了以下三种策略:
通过配置 server.lfu_log_factor 参数来 调整计数器的增长速率。
- 该参数越大,计数器的增长速率越慢。
通过配置 server.lfu_decay_time 参数来 调整计数器的衰减速率。
- 该参数决定计数器在多长时间内衰减到最小频率。
通过设置 LFU_INIT_VAL 变量的值来 调整计数器的初始值。
- 默认值为 5。
Window-LFU
Window-LFU 是 LFU 淘汰策略的一种变体。
和传统的 LFU 一样,Window-LFU 也会跟踪缓存中 key 的访问频率,目的是识别和移出访问频率最低的 key。
但是不同于传统的 LFU,它每次访问一个 key 时,使用滑动窗口的方法来更新追踪 key 的访问频率。
在 Window-LFU 中,缓存被分成一系列固定大小的窗口,每个窗口都会跟踪 key 的访问频率。当访问一个 key 时,它的计数器会在当前窗口中增加。随着时间的推移,窗口会向前滑动,每个 key 的计数器都会减少,这样计数器就会反映出 key 在当前窗口中的访问频率。当缓存达到容量时,计数器较低的 key 会被标记为淘汰的候选者。
Window-LFU 是非常有吸引力的,因为它可以适应随着时间的推移而变化的访问模式,并且已经被证明在各种设置中表现良好。但是,它在实践中并不广泛使用,也没有在 Redis 等流行的缓存应用中实现。
总结
在这篇文章中,我们介绍了 LFU(Least Frequently Used)淘汰策略,它是一种缓存淘汰策略,用来跟踪缓存中 key 的访问频率,并淘汰访问频率最低的 key。同时,我们还介绍了 LFU 的两个变体,LFU-Aging 和 Window-LFU,它们旨在通过考虑 key 的年龄以及使用滑动窗口方法来跟踪 key 的访问频率来解决 LFU 潜在的性能问题。
参考资料
An O(1) algorithm for implementing the LFU cache eviction scheme
最后修改于 2023-02-03
感谢您的支持 :D